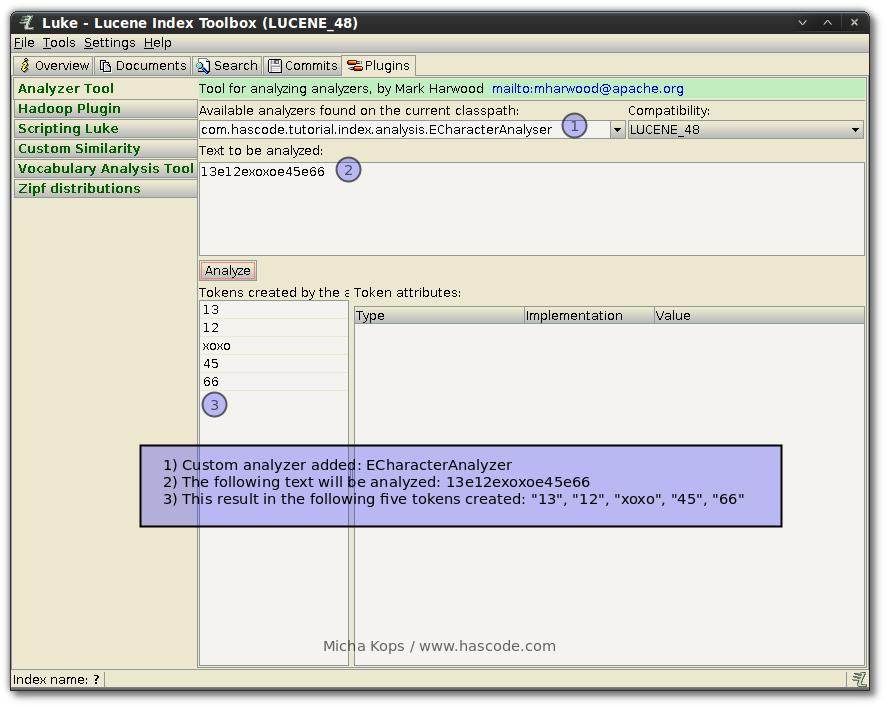
Elasticsearch Integration Testing with Java
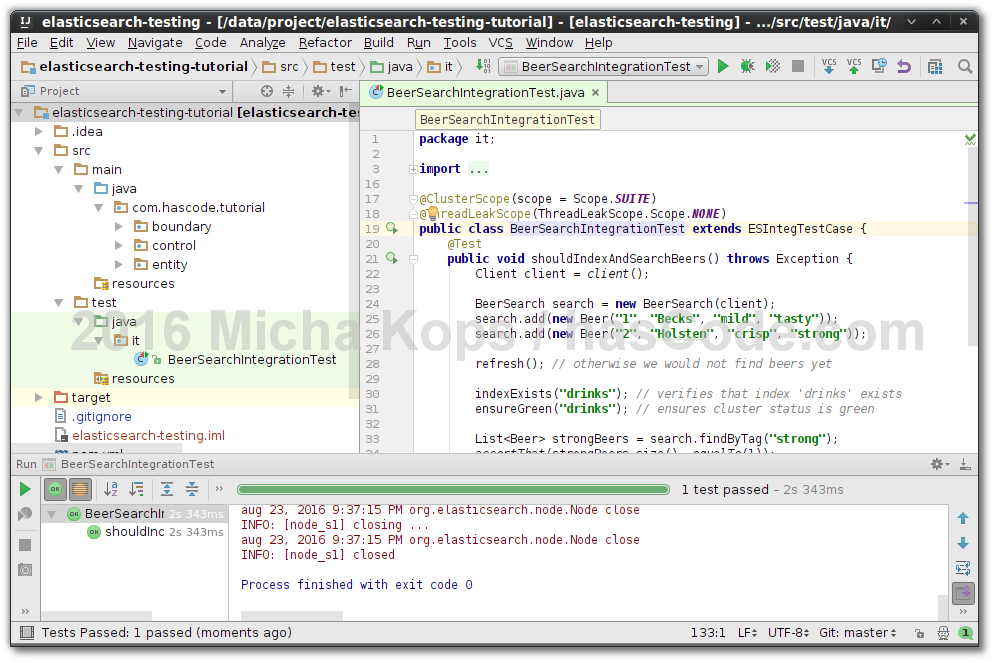
When building up search engines, indexing tons of data into a schema-less, distributed data store, Elasticsearch has always been a favourite tool of mine. In addition to its core features, it also offers tools and documentation for us developers when we need to write integration tests for our Elasticsearch powered Java applications. In the following tutorial I’d like to demonstrate how to implement a small sample application using Elasticsearch under the hood and how to write integration-tests with these tools for this application afterwards. ...