Lucene by Example: Specifying Analyzers on a per-field-basis and writing a custom Analyzer/Tokenizer
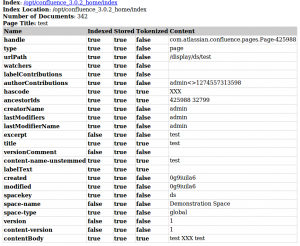
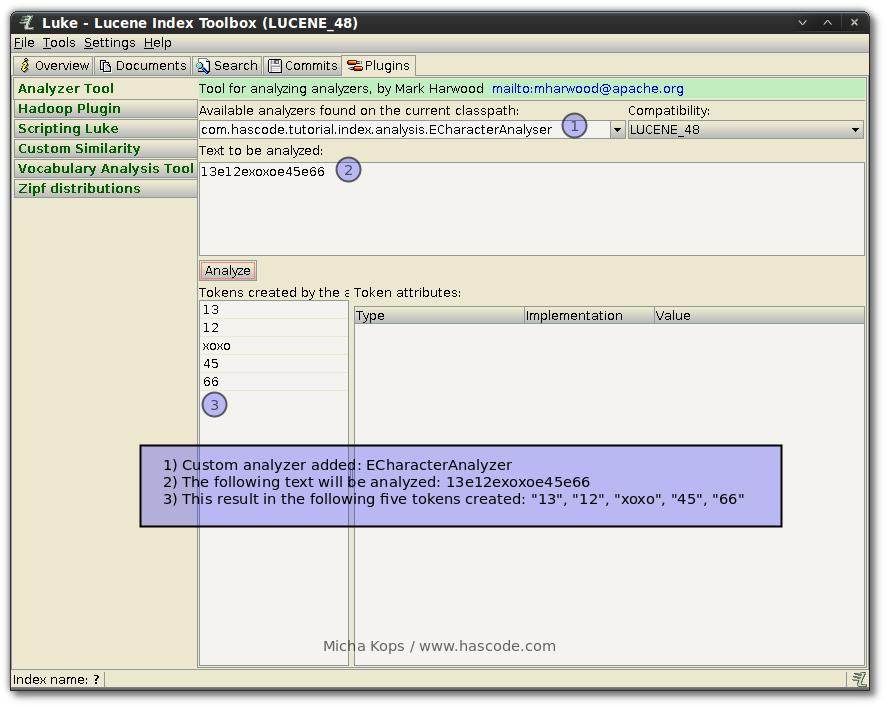
Lucene is my favourite search engine library and the more often I use it in my projects the more features or functionality I find that were unknown to me. Two of those features I’d like to share in the following tutorial is one the one hand the possibility to specify different analyzers on a per-field basis and on the other hand the API to create a simple character based tokenizer and analyzer within a few steps. ...