Querydsl is a framework that allows us to create elegant, type-safe queries for a variety of different data-sources like Java Persistence API (JPA) entities, Java Data Objects (JDO), mongoDB with Morphia, SQL, Hibernate Search up to Lucene.
In the following tutorial we’re implementing example queries for different environments – Java Persistence API compared with a JPQL and a criteria API query, mongoDB with Morphia and last but not least for Lucene.

Querydsl vs JPA (JPQL and Criteria API)
First of all we’re starting to write some queries for a persistence layer using the Java Persistence API and as a comparison we’ll be adding traditional JPA queries using the JPA query language and the criteria API.
Dependencies
I’m using Maven to add needed dependencies here, but if we need to use another build system like Gradle or SBT it should not be a problem to transfer this information into the corresponding system – especially because the dependencies are available on the global Maven repository.
This is a snippet from my project’s pom.xml .. please note that we’re recycling com.mysema.querydsl:querydsl-apt for all of the other following examples, too.
Besides we’re adding the dependency for querydsl-jpa and we’re using the apt-maven-plugin to generate the metamodel sources from our entities. The JPAAnnotationProcessor scans for classes annotated with @Entity and generates meta-model classes for query construction in target/generated/sources/java.
If you’re not using an IDE with a good Maven builder you might need to recreate your project file to include the directory with the generated sources .. e.g. by running the following command (for Eclipse IDE): mvn eclipse:eclipse
<properties>
<querydsl.version>3.3.0</querydsl.version>
</properties>
<dependency>
<groupId>com.mysema.querydsl</groupId>
<artifactId>querydsl-apt</artifactId>
<version>${querydsl.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.mysema.querydsl</groupId>
<artifactId>querydsl-jpa</artifactId>
<version>${querydsl.version}</version>
</dependency>
<build>
<plugins>
<plugin>
<groupId>com.mysema.maven</groupId>
<artifactId>apt-maven-plugin</artifactId>
<version>1.0.9</version>
<executions>
<execution>
<goals>
<goal>process</goal>
</goals>
<configuration>
<outputDirectory>target/generated-sources/java</outputDirectory>
<processor>com.mysema.query.apt.jpa.JPAAnnotationProcessor</processor>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>Persistence Context and Entities
Since we’re using the Java Persistence API we first need to setup some entities and the persistence context.
You might want to#Querydsl_Exampleskip directly to the query examples if not interested in the setup.
Book
This is our book entity .. a book has an identifier, a title, a publication date and references to its author and a list of tags.
@Entity
public class Book {
@Id
@GeneratedValue
private Long id;
private String title;
private Author author;
@Temporal(TemporalType.DATE)
private Date published;
@OneToMany(cascade = CascadeType.ALL)
private final List<Tag> tags = new ArrayList<>();
// getter, setter ...
}Author
An author simply has an identifier, a name and a back-reference to his books.
@Entity
public class Author {
@Id
@GeneratedValue
private Long id;
private String name;
@OneToMany
private final List<Book> books = new ArrayList<>();
// getter, setter ....
}Tag
Tags are quite simply .. they’ve got a name .. and nothing else …
@Entity
public class Tag {
@Id
private String name;
// getter, setter
}Persistence Configuration
Last but not least, we need some configuration for the persistence provider .. so this is my persistence.xml to be put in src/main/resources/META-INF.
I’m using an HSQL database here, if you’re interested in the complete setup, please feel free to skip to the tutorial sources that includes running examples.
<persistence xmlns="http://java.sun.com/xml/ns/persistence"
version="1.0">
<persistence-unit name="default" transaction-type="RESOURCE_LOCAL">
<properties>
<property name="javax.persistence.jdbc.driver" value="org.hsqldb.jdbcDriver" />
<property name="javax.persistence.jdbc.url" value="jdbc:hsqldb:mem:testdb" />
<property name="javax.persistence.jdbc.user" value="sa" />
<property name="javax.persistence.jdbc.password" value="" />
<property name="eclipselink.ddl-generation" value="create-tables" />
</properties>
<exclude-unlisted-classes>false</exclude-unlisted-classes>
</persistence-unit>
</persistence>Querydsl Example
Now we’re ready for some JPA, Querydsl fun … but one thing needs to be done before .. we need some persisted entities in our database to query for …
EntityManager em = Persistence.createEntityManagerFactory("default")
.createEntityManager();
EntityTransaction tx = em.getTransaction();
tx.begin();
Calendar cal1 = Calendar.getInstance();
cal1.set(2010, 0, 0);
Calendar cal2 = Calendar.getInstance();
cal2.set(2011, 0, 0);
Author author = new Author("Some Guy");
em.persist(author);
Tag horrorTag = new Tag("Horror");
Tag dramaTag = new Tag("Drama");
Tag scienceTag = new Tag("Science");
Book b1 = new Book();
b1.setTitle("The big book of something");
b1.setAuthor(author);
b1.setPublished(cal2.getTime());
b1.addTag(horrorTag);
b1.addTag(dramaTag);
b1.addTag(scienceTag);
Book b2 = new Book();
b2.setTitle("Another book");
b2.setAuthor(author);
Book b3 = new Book();
b3.setTitle("The other book of something");
b3.setAuthor(author);
b3.setPublished(cal2.getTime());
b3.addTag(dramaTag);
em.persist(b1);
em.persist(b2);
em.persist(b3);Now we’re able (given that the metaclasses were generated) to construct an elegant query using Querydsl like this one:
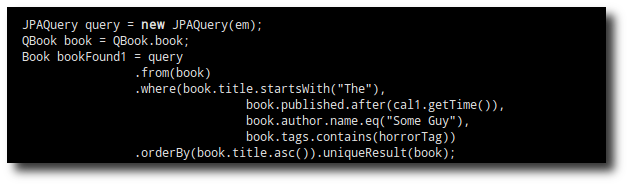
JPAQuery query = new JPAQuery(em);
QBook book = QBook.book;
Book bookFound1 = query
.from(book)
.where(book.title.startsWith("The"),
book.published.after(cal1.getTime()),
book.author.name.eq("Some Guy"),
book.tags.contains(horrorTag))
.orderBy(book.title.asc()).uniqueResult(book);
System.out.println("Using Querydsl:\t\t\t" + bookFound1.toString());Running the code should produce a similar output:
Using Querydsl: Book [id=2, title=The big book of something, author=Author [id=1, name=Some Guy], published=Fri Dec 31 16:55:00 CET 2010, tags=[Tag [name=Horror], Tag [name=Drama], Tag [name=Science]]]vs JPQL
Now as a comparison we’re creating a non type-safe query using JPA’s query language:
Book bookFound3 = em
.createQuery(
"SELECT book FROM Book book WHERE book.title LIKE 'The%' AND book.published>:published AND book.author.name=:author AND :tag MEMBER OF book.tags ORDER BY book.title ASC",
Book.class).setParameter("published", cal1.getTime())
.setParameter("author", "Some Guy")
.setParameter("tag", new Tag("Horror")).getSingleResult();
System.out.println("Using JPA Query Language:\t"
+ bookFound3.toString());The code above produces a similar output:
Using JPA Criteria API: Book [id=2, title=The big book of something, author=Author [id=1, name=Some Guy], published=Fri Dec 31 16:55:00 CET 2010, tags=[Tag [name=Horror], Tag [name=Drama], Tag [name=Science]]]vs Criteria API
Last but not least a fast written example of the same query using the JPA criteria API:
// Using JPA Criteria API
CriteriaBuilder cb = em.getCriteriaBuilder();
CriteriaQuery<Book> cq = cb.createQuery(Book.class);
Root<Book> bk = cq.from(Book.class);
cq.select(bk);
Expression<List<Tag>> tags = bk.get("tags");
cq.where(cb.like(bk.get("title").as(String.class), "The%"),
cb.greaterThan(bk.get("published").as(Date.class),
cal1.getTime()), cb.equal(bk.get("author").get("name")
.as(String.class), "Some Guy"), cb.isMember(horrorTag,
tags));
cq.orderBy(cb.asc(bk.get("title")));
Book bookFound2 = em.createQuery(cq).getSingleResult();
System.out.println("Using JPA Criteria API:\t\t"
+ bookFound2.toString());Again a similar output is produced:
Using JPA Query Language: Book [id=2, title=The big book of something, author=Author [id=1, name=Some Guy], published=Fri Dec 31 16:55:00 CET 2010, tags=[Tag [name=Horror], Tag [name=Drama], Tag [name=Science]]]mongoDB and Morphia
In the next example we’re using Querydsl combined with mongoDB and Morphia. Morphia itself is a framework that allows us to map entities and their references as we’re used from a JPA environment but ending in the schema-less mongoDB database.
Dependencies
The following dependencies are needed to run the examples below. I am using flapdoodle-embedded-mongo here to setup a mongoDB for test purposes in no time.
Again we’re using the apt-maven-plugin and the MorhpiaAnnotationProcessor to create the meta-model classes for us.
<dependency>
<groupId>com.mysema.querydsl</groupId>
<artifactId>querydsl-mongodb</artifactId>
<version>${querydsl.version}</version>
<classifier>apt</classifier>
</dependency>
<dependency>
<groupId>org.mongodb</groupId>
<artifactId>mongo-java-driver</artifactId>
<version>2.11.4</version>
</dependency>
<dependency>
<groupId>de.flapdoodle.embed</groupId>
<artifactId>de.flapdoodle.embed.mongo</artifactId>
<version>1.42</version>
</dependency>
<dependency>
<groupId>org.mongodb.morphia</groupId>
<artifactId>morphia</artifactId>
<version>0.105</version>
</dependency>
<build>
<plugins>
<plugin>
<groupId>com.mysema.maven</groupId>
<artifactId>apt-maven-plugin</artifactId>
<version>1.0.9</version>
<executions>
<execution>
<goals>
<goal>process</goal>
</goals>
<configuration>
<outputDirectory>target/generated-sources/java</outputDirectory>
<processor>com.mysema.query.apt.morphia.MorphiaAnnotationProcessor</processor>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>Entities
Again we’re adding some entities with basic relations.. please note that we’re not using JPA’s @Entity here but org.mongodb.morphia.annotations.Entity
Book
This is our book entity .. again a book has an identifier, a title, an author and a list of tags ..
@Entity("books")
public class Book {
@Id
private ObjectId id;
private String title;
private Author author;
private Date published;
@Reference
private final List<Tag> tags = new ArrayList<>();
// getter, setter
}Author
As in the JPA example, an author has an identifier and a name ..
@Entity
public class Author {
@Id
private ObjectId id;
private String name;
// getter, setter
}Tag
A tag also has an identifier and a name…
@Entity
public class Tag {
@Id
private ObjectId id;
private String name;
}Querydsl Example
In this example, we’re setting up a new mongoDB database, we’re adding some books and finally we’re running a Querydsl query to search for books with a set of different criteria…
String dbName = "testdb";
new MongodForTestsFactory();
MongoClient client = MongodForTestsFactory
.with(Version.Main.PRODUCTION).newMongo();
Morphia morphia = new Morphia()
.map(Book.class, Author.class, Tag.class);
Datastore ds = morphia.createDatastore(client, dbName);
Calendar cal1 = Calendar.getInstance();
cal1.set(2010, 0, 0);
Calendar cal2 = Calendar.getInstance();
cal2.set(2011, 0, 0);
Author author = new Author("Some guy");
ds.save(author);
Tag horrorTag = new Tag("Horror");
Tag dramaTag = new Tag("Drama");
Tag scienceTag = new Tag("Science");
ds.save(horrorTag);
ds.save(dramaTag);
ds.save(scienceTag);
Book b1 = new Book();
b1.setTitle("The big book of something");
b1.setAuthor(author);
b1.setPublished(cal2.getTime());
b1.addTag(horrorTag);
b1.addTag(dramaTag);
b1.addTag(scienceTag);
Book b2 = new Book();
b2.setTitle("Another book");
b2.setAuthor(author);
Book b3 = new Book();
b3.setTitle("The other book of something");
b3.setAuthor(author);
b3.setPublished(cal2.getTime());
b3.addTag(dramaTag);
ds.save(b1);
ds.save(b2);
QBook book = QBook.book;
MorphiaQuery<Book> query = new MorphiaQuery<Book>(morphia, ds, book);
List<Book> books = query.where(book.title.startsWith("The"),
book.published.after(cal1.getTime()),
book.author.name.eq("Some guy"), book.tags.contains(horrorTag))
.list();
for (Book bookFound : books) {
System.out.println(bookFound.toString());
}Running the example above produces the following output:
Book [id=52fa7cf10fcee8e5948a548b, title=The big book of something, author=Author [id=52fa7cf10fcee8e5948a5487, name=Some guy], published=Fri Dec 31 20:41:37 CET 2010, tags=[Tag [id=52fa7cf10fcee8e5948a5488, name=Horror], Tag [id=52fa7cf10fcee8e5948a5489, name=Drama], Tag [id=52fa7cf10fcee8e5948a548a, name=Science]]]Lucene
In our last example, we’re going to write some queries to find documents from a Lucene index.
Dependencies
We need a bunch of dependencies here, first of all querydsl-lucene4 (querydsl-lucene3 does also exist!) and some common Lucene libraries for analyzers, parsers and stuff..
<properties>
<lucene.version>4.6.0</lucene.version>
</properties>
<dependencies>
<dependency>
<groupId>com.mysema.querydsl</groupId>
<artifactId>querydsl-lucene4</artifactId>
<version>${querydsl.version}</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>${lucene.version}</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>${lucene.version}</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queries</artifactId>
<version>4.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-misc</artifactId>
<version>4.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-sandbox</artifactId>
<version>4.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>4.6.0</version>
</dependency>
<dependency>
<groupId>joda-time</groupId>
<artifactId>joda-time</artifactId>
<version>2.3</version>
</dependency>
</dependencies>Creating the Query Type
Lucene has no schema so we need to write our meta-model by hand. Because of the special nature of a Lucene index, you might notice that not every query type is possible in this scenario.
This is done by extending com.mysema.query.types.path.EntityPathBase and specifying the different path elements that are subclasses of com.mysema.query.types.Path.
public class QBook extends EntityPathBase<Document> {
private static final long serialVersionUID = 1L;
public QBook(final String var) {
super(Document.class, PathMetadataFactory.forVariable(var));
}
public final StringPath title = createString("title");
public final StringPath author = createString("author");
public final DatePath<LocalDate> published = createDate("published",
LocalDate.class);
public final NumberPath<Float> price = createNumber("price", Float.class);
}Now we’re ready to construct queries with Querydsl.
Querydsl Example
In the following example, we’re adding a bunch of books to an in-memory Lucene index and we’re constructing a query using the Querydsl syntax afterwards to search for books from the index.
LocalDate date1 = new LocalDate(2010, 1, 1);
LocalDate date2 = new LocalDate(2011, 2, 13);
Directory index = new RAMDirectory();
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_46);
IndexWriterConfig iwc = new IndexWriterConfig(Version.LUCENE_46,
analyzer).setOpenMode(OpenMode.CREATE);
IndexWriter writer = new IndexWriter(index, iwc);
createBook(writer, "The big book of something", "Some Guy", date1,
20.50F);
createBook(writer, "Another book of something", "Arthur Someone",
date2, 13.5F);
createBook(writer, "Anything, onething, something", "Some Guy", date1,
29.99F);
createBook(writer, "Something, somewhere", "Some Guy", date1, 9.50F);
writer.commit();
writer.close();
QBook book = new QBook("book");
IndexReader reader = DirectoryReader.open(index);
System.out.println(reader.numDocs() + " books stored in index");
IndexSearcher searcher = new IndexSearcher(reader);
LuceneQuery query = new LuceneQuery(new LuceneSerializer(true, true),
searcher);
System.out.println("Searching a Lucene Index with Querydsl");
LuceneQuery bookQuery = query.where(book.author.eq("Some Guy"),
book.published.before(date2), book.price.between(10.F, 30.F),
book.title.endsWith("something")).orderBy(book.title.asc());
System.out.println("generated lucene query: " + bookQuery.toString());
List<Document> documents = bookQuery.list();
System.out.println(documents.size() + " books found");
for (Document doc : documents) {
System.out.println(doc);
}
private void createBook(final IndexWriter writer, final String title,
final String author, final LocalDate published, final float price)
throws IOException {
Document doc = new Document();
doc.add(new TextField("title", title, Store.YES));
doc.add(new TextField("author", author, Store.YES));
doc.add(new StringField("published", published.toString(), Store.YES));
doc.add(new FloatField("price", price, Store.YES));
writer.addDocument(doc);
}Running the examples above should produce the following output:
4 books stored in index
Searching a Lucene Index with Querydsl
generated lucene query: +(+(+author:"some guy" +published:{* TO 2011-02-13}) +price:[10.0 TO 30.0]) +title:*something
2 books found
Document<stored,indexed,tokenized<title:The big book of something> stored,indexed,tokenized<author:Some Guy> stored,indexed,tokenized,omitNorms,indexOptions=DOCS_ONLY<published:2010-01-01> stored<price:20.5>>
Document<stored,indexed,tokenized<title:Anything, onething, something> stored,indexed,tokenized<author:Some Guy> stored,indexed,tokenized,omitNorms,indexOptions=DOCS_ONLY<published:2010-01-01> stored<price:29.99>>Tutorial Sources
Please feel free to download the tutorial sources from my GitHub repository, fork it there or clone it using Git:
git clone https://github.com/hascode/querydsl-tutorial.git